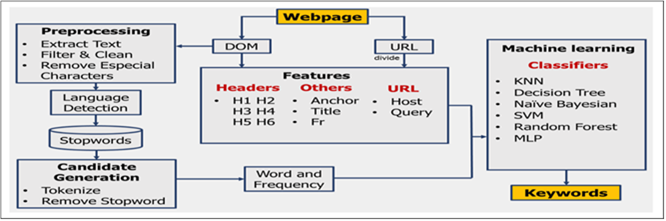
import sys
from collections import defaultdict
import re
import numpy as np
import lxml
import sys
import math
import urllib
import nltk
from nltk import wordpunct_tokenize
import sys
from bs4 import BeautifulSoup
from bs4.element import Comment
from collections import defaultdict,Counter
from nltk.corpus import stopwords
STP_SET_ENG_NLTK = set(stopwords.words("english"))
F_stopwords = set(stopwords.words("finnish"))
url_unused_words = ['','https','www','com','-','php','pk','fi','https:','http','http:','html','htm']
english_stop_words =[x for x in STP_SET_ENG_NLTK]
finnish_stop_words =[x for x in F_stopwords]
combine_stopwords = english_stop_words + finnish_stop_words
def Scrapper1(element):
if element.parent.name in ['html','style', 'script']:
return False
if isinstance(element, Comment):
return False
return True
def Scrapper2(body): #text_from_html(body):
soup = BeautifulSoup(body, 'lxml')
texts = soup.findAll(text=True)
name =soup.findAll(name=True)
visible_texts = filter(Scrapper1,texts)
return u" ".join(t.strip() for t in visible_texts)
#raw =Scrapper2(html)#text
def Scrapper3(text):
lines = (line.strip() for line in text.splitlines()) # break into lines and remove leading and trailing space on each
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))# break multi-headlines into a line each
return u'\n'.join(chunk for chunk in chunks if chunk)# drop blank lines
def Scrapper_title_4(urls):
req = urllib.request.Request(urls, headers={'User-Agent' : "Magic Browser"})
con = urllib.request.urlopen(req)
html= con.read()
title=[]
soup = BeautifulSoup(html, 'lxml')
title.append(soup.title.string)
return(title,urls)
def Web(urls):
req = urllib.request.Request(urls, headers={'User-Agent' : "Magic Browser"})
con = urllib.request.urlopen(req)
html= con.read()
soup = BeautifulSoup(html, 'lxml') #keywordregex = re.compile('')
raw =Scrapper2(html)
clean_text=Scrapper3(raw)
return(clean_text,soup)
# Detect language and stopwords list
def _calculate_languages_ratios(text):
languages_ratios = {}
tokens = wordpunct_tokenize(text)
words = [word.lower() for word in tokens]
for language in stopwords.fileids():
stopwords_set = set(stopwords.words(language))
words_set = set(words)
common_elements = words_set.intersection(stopwords_set)
languages_ratios[language] = len(common_elements) # language "score"
return languages_ratios
def detect_language(text):
ratios = _calculate_languages_ratios(text)
most_rated_language = max(ratios, key=ratios.get)
stop_words_for_language = set(stopwords.words(most_rated_language))
return most_rated_language,stop_words_for_language
def extract_stop_words(detected_language):
stop_words =[]
language_name = detected_language[0]
for x in detected_language:
for i in x:
stop_words.append (i)
return (language_name,stop_words)
#Preprocess
def Text_Clean(Text,stopwords):
clean_text =[]
k=[]
filter_text = [x.lower().strip().replace('.','').replace('‘','').replace('"','').replace('\'','').replace('?','').replace(',','').replace('-','').replace(':','').replace('!','').replace('@','').replace(')','').replace('(','').replace('#','').replace('%','').replace('"','').replace('/','').replace('\\','').replace('~','').replace('’','').replace('”','').replace(';','').replace('–','').replace('\\','').replace(" ",'').replace('/n','').replace('\n','').replace('…','').replace('“','').strip() for x in Text.split()]
for word in filter_text:
[clean_text.append(x)for x in word.split() if x not in stopwords and len(x)>1 and x.isalpha()]
return(clean_text)
# Features Formations
def Divide_Url(url):
from urllib.parse import urlparse
host=[]
obj=urlparse(url)
name =(obj.hostname)
for x in name.split('.'):
if x.lower() not in url_unused_words:
host.append(x)
return(host)
def Divide_URL_HOST_QUERY (URL):
path=[]
host =Divide_Url(URL)
for x in URL.split('/'):
for i in x.split('.'):
for d in i.split('-'):
if d.lower() not in url_unused_words and d.lower() not in host:
path.append(d.lower())
host_dic = COUNTER_DICT(host)
path_dic = COUNTER_DICT(path)
return(host_dic,path_dic)
def get_text(soup,h):
text=[]
text2 =[]
text_dic ={}
for w in soup.find_all(h):
h_text = w.text.strip()
h_text =h_text.replace(':','') #change made here
h_text =h_text.replace(',','')
h_text =h_text.replace('|','')
h_text =(h_text.lower())
#change made here
for x in h_text.split('-'):
text.append(x)
if len(text)!=0:
for x in text:
word=[n.strip() for n in x.split(',')]
for x in word:
words=[i.strip() for i in x.split() ]
for x in words:
text2.append(x)
text_dic = COUNTER_DICT(text2)
return(text_dic)
else:
return(text_dic)
def CHEK_NULL(word,dic):
f =0
if len(dic)>=1:
f = dic.get(word)
else:
f =0
if f is None:
f =0
return (f)
def Extract_headerAnchorTitle(soup):
h1_d= get_text(soup,'h1')
h2_d= get_text(soup,'h2')
h3_d=get_text(soup,'h3')
h4_d= get_text(soup,'h4')
h5_d= get_text(soup,'h5')
h6_d= get_text(soup,'h6')
a_d= get_text(soup,'a') #alt tab or anchor
title_d= get_text(soup,'title') #CALLing
return(h1_d,h2_d,h3_d,h4_d,h5_d,h6_d,a_d,title_d)
# Manual Score each Feature
def GET_SCORE_EACH_FEATURE(word,h1_dic, h2_dic,h3_dic,h4_dic,h5_dic,h6_dic,A_dic,title_dic,URL_H_dic,URL_Q_dic):
f1 = CHEK_NULL(word,h1_dic)
f2 = CHEK_NULL(word,h2_dic)
f3 = CHEK_NULL(word,h3_dic)
f4 = CHEK_NULL(word,h4_dic)
f5 = CHEK_NULL(word,h5_dic)
f6 = CHEK_NULL(word,h6_dic)
f7 = CHEK_NULL(word,A_dic)
f8 = CHEK_NULL(word,title_dic)
f9 = CHEK_NULL(word,URL_H_dic)
f10 = CHEK_NULL(word,URL_Q_dic)
return (f1,f2,f3,f4,f5,f6,f7,f8,f9,f10)
def COUNTER_DICT(list_words):
score_dic ={}
if len (list_words)>=1:
list_words = [x for x in list_words if x not in combine_stopwords and len(str(x))>1 and str(x).isalpha() ]
word_count_dict ={}
unique_list =[]
[unique_list.append(x) for x in list_words if x not in unique_list]
lngth_list = len(unique_list)
counter_list = Counter(list_words)
word_fr_dic ={}
for word,fr in counter_list.most_common():
word_fr_dic[word]= fr
for word in unique_list:
fr = word_fr_dic.get(word)
fr_word = fr/lngth_list
score_dic[word]= fr_word
return (score_dic)
else:
return ()
def WebRank(URL):
Text,HTML = Web(URL)
detected_language = detect_language(Text)
name,stop_words =extract_stop_words(detected_language)
candidate_list = Text_Clean(Text,stop_words)
candidate_dic= COUNTER_DICT(candidate_list)
unique_candidate_list =[]
[unique_candidate_list.append(x) for x in candidate_list if x not in unique_candidate_list if x not in STP_SET_ENG_NLTK and x not in stop_words and len(x)>1 and x.isalpha()]
#Features
URL_H_dic,URL_Q_dic = Divide_URL_HOST_QUERY(URL)
h1_dic, h2_dic,h3_dic,h4_dic,h5_dic,h6_dic,A_dic,title_dic = Extract_headerAnchorTitle(HTML)
# Column headers
string="Word,Relative Frequency %,H1%,H2%,H3%,H4%,H5%,H6%,Anchor%,Title%,Url-Host,Url-Query,GT,web-id";
for word in unique_candidate_list:
try:
fr = candidate_dic.get(word)
if fr is None or not fr:
fr =0
f1,f2,f3,f4,f5,f6,f7,f8,f9,f10 = GET_SCORE_EACH_FEATURE(word,h1_dic, h2_dic,h3_dic,h4_dic,h5_dic,h6_dic,A_dic,title_dic,URL_H_dic,URL_Q_dic)
f12 = 0
f11 =0
string+="\n"+word+",";
string+=str(fr)+",";
string+=str(f1)+",";
string+=str(f2)+",";
string+=str(f3)+",";
string+=str(f4)+",";
string+=str(f5)+",";
string+=str(f6)+",";
string+=str(f7)+",";
string+=str(f8)+",";
string+=str(f9)+",";
string+=str(f10)+",";
string+=str(f11)+",";
string+=str(f12);
except:
continue
return (string,Text)
if __name__ == "__main__":
URL ="http://bbc.com"
word__plus_featuresScore , Text_webpage = WebRank(URL)
(2)Features testing and Training Section
(1) Common.py
import math;
def readData(filename):
from numpy import genfromtxt
import numpy as np
data = genfromtxt(filename, delimiter=' ')
labels=[];
webpageIndex=[];
features=[];
if(type(data[0]) is np.float64):
features.append(data[:-2]);
labels.append(data[-2]);
webpageIndex.append(data[-1]);
else:
for i in range(0,len(data)):
features.append(data[i][:-2]);
labels.append(data[i][-2]);
webpageIndex.append(data[i][-1]);
return {
"features":features,
"labels":labels,
"webpageIndices":webpageIndex
};
def printStatistics(predicted,labels,indices):
import numpy as np
indicesSet=set(indices);
resultString="";
oldIndex=-1;
keywordIndices="";
binaryValues="";
for i in range(0,len(indices)):
binaryValues=binaryValues+str(math.floor(predicted[i]))+"\n";
if(oldIndex!=indices[i]): # webpage id is indices[i]
if(oldIndex!=-1):
resultString=resultString+str(math.floor(oldIndex))+" "+keywordIndices+"\n";
if(predicted[i]==1):
if(keywordIndices!=""):
keywordIndices+=" ";
keywordIndices+=str(i);
if(oldIndex!=-1):
if(predicted[i]==1):
keywordIndices=str(i);
else:
keywordIndices="";
oldIndex=indices[i];
else:
if(predicted[i]==1):
if(keywordIndices!=""):
keywordIndices+=" ";
keywordIndices+=str(i);
resultString=resultString+str(math.floor(oldIndex))+" "+keywordIndices+"\n";
return [resultString,binaryValues];
def save(model, filename):
from sklearn.externals import joblib
joblib.dump(model, filename)
def load(filename):
from sklearn.externals import joblib
return joblib.load(filename)
def getHighestProbabilities(scores,indices,top):
import numpy as np
indicesSet=set(indices);
predicted=np.zeros(len(scores));
for val in indicesSet:
scoresInSet=[];
minIndex=len(indices);
for i in range(0,len(indices)):
if(indices[i]==val):
scoresInSet.append(scores[i]);
minIndex=min(minIndex,i);
ids=np.argsort(scoresInSet);
marksInSet=np.zeros(len(scoresInSet));
adjustedTop=min(top,len(scoresInSet));
for i in range(0,len(marksInSet)):
if(i>=len(marksInSet)-adjustedTop):
marksInSet[ids[i]]=1;
for i in range(0,len(indices)):
if(indices[i]==val):
if(marksInSet[i-minIndex]==1):
predicted[i]=1;
return predicted;
(2) Max_Score.py
# Predicts the top k(10) keywords
# 3.7.2019: RM - Implemented
def scoreEachWebpageKeywords(features,indices,top):
import numpy as np
predicted = np.zeros(len(features));
scores=np.zeros(len(features));
for i in range (0,len(features)):
# Himat's scoring Drank method
tfscore=0.5*features[i][0]
if(features[i][11]>50):
tfscore=0.2*features[i][0]
scores[i]= min(1,features[i][1]) *6
scores[i]+=min(1,features[i][2]) *5
scores[i]+=min(1,features[i][3]) *3
scores[i]+=min(1,features[i][4]) *2
scores[i]+=min(1,features[i][5]) *2
scores[i]+=min(1,features[i][6]) *2
#anchor
scores[i]+=min(1,features[i][7]) *1
#title
scores[i]+=min(1,features[i][8]) *6;
#url Host
scores[i]+=min(1,features[i][9]) *5;
#url Query
scores[i]+=min(1,features[i][10])*4;
scores[i]+= tfscore *1;
predicted=common.getHighestProbabilities(scores,indices,top);
return predicted;
import common
import sys
# PARAMETERS
fold=1;
dataset="mopsi_services";#guardian,macworld,mopsi_services
top=10;
if(len(sys.argv)>1):
dataset=sys.argv[1];
if(len(sys.argv)>2):
fold=int(sys.argv[2]);
if(len(sys.argv)>3):
top=int(sys.argv[3]);
inFile="/home/tko/himat/web-docs/machine_learning/txt_files_datasets/"+dataset+"/testing_"+str(fold)+".txt";
# DATA + MODEL READING
data=common.readData(inFile);
# PREDICTING
predicted=scoreEachWebpageKeywords(data["features"],data["webpageIndices"],top)
# OUTPUT STATISTICS
[resultString,binaryValues]=common.printStatistics(predicted,data["labels"],data["webpageIndices"]);
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/testing_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(resultString);
f.close();
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/binary_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(binaryValues);
f.close();
(3) KNN Training and Testing
(3.1) KNN Training
# Trains an KNN model
# Stores it in a file Number of neighbors is parameter
import common
import sys
from sklearn.neighbors import KNeighborsClassifier
# PARAMETERS
inFile="../training.txt";
outFile="/home/tko/himat/web-docs/machine_learning/classification/models/knn.joblib";
k=2; #default
if(len(sys.argv)>1):
dataset=sys.argv[1];
if(len(sys.argv)>2):
fold=int(sys.argv[2]);
if(len(sys.argv)>3):
k=int(sys.argv[3]);
inFile="/home/tko/himat/web-docs/machine_learning/txt_files_datasets/"+dataset+"/testing_"+str(fold)+".txt";
# DATA READING
data=common.readData(inFile);
# TRAINING
model = KNeighborsClassifier(n_neighbors=k)
model.fit(data["features"], data["labels"])
# SAVING MODEL
common.save(model,outFile);
print ("Model saved at %s" % (outFile));
(3.2) KNN Test
# Reads an KNN model from a file and performs prediction
import common
import sys
from sklearn import svm
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import confusion_matrix, accuracy_score, f1_score, precision_score, recall_score
# PARAMETERS
inFile="../testing.txt";
outFile="/home/tko/himat/web-docs/machine_learning/classification/models/knn.joblib";
top=10;#default
if(len(sys.argv)>1):
dataset=sys.argv[1];
if(len(sys.argv)>2):
fold=int(sys.argv[2]);
if(len(sys.argv)>3):
top=int(sys.argv[3]);
inFile="/home/tko/himat/web-docs/machine_learning/txt_files_datasets/"+dataset+"/testing_"+str(fold)+".txt";
# DATA + MODEL READING
data=common.readData(inFile);
model=common.load(outFile);
# PREDICTING
predicted=model.predict(data["features"])
probabilities=model.predict_proba(data["features"])
import numpy as np
scores=np.zeros(len(probabilities));
for i in range (0,len(probabilities)):
scores[i]=probabilities[i][1];
newPredicted=common.getHighestProbabilities(scores,data["webpageIndices"],top);
# OUTPUT STATISTICS
[resultString,binaryValues]=common.printStatistics(newPredicted,data["labels"],data["webpageIndices"]);
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/testing_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(resultString);
f.close();
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/binary_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(binaryValues);
f.close();
(4) Bayes train and Test
(4.1) Bayes Train
# Trains a Bayes model and stores it in a file
# Bayes Train
import common
import sys
from sklearn.naive_bayes import GaussianNB
# PARAMETERS
output="../output/";
input="../input/";
inFile="train.txt";
outFile="/home/tko/himat/web-docs/machine_learning/classification/models/bayes.joblib";
if(len(sys.argv)>1):
dataset=sys.argv[1];
if(len(sys.argv)>2):
fold=int(sys.argv[2]);
inFile="/home/tko/himat/web-docs/machine_learning/txt_files_datasets/"+dataset+"/testing_"+str(fold)+".txt";
# DATA READING
data=common.readData(inFile);
# TRAINING
model = GaussianNB()
model.fit(data["features"][:-1], data["labels"][:-1])
# # SAVING MODEL
common.save(model,outFile);
print ("Model saved at %s" % (outFile));
(4.2) Bayes Test
# Reads a Bayes model from a file and performs prediction
import common
import sys
from sklearn import svm
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import confusion_matrix, accuracy_score, f1_score, precision_score, recall_score
# PARAMETERS
inFile="../testing.txt";
outFile="/home/tko/himat/web-docs/machine_learning/classification/models/bayes.joblib";
top=10;#default
if(len(sys.argv)>1):
dataset=sys.argv[1];
if(len(sys.argv)>2):
fold=int(sys.argv[2]);
if(len(sys.argv)>3):
top=int(sys.argv[3]);
inFile="/home/tko/himat/web-docs/machine_learning/txt_files_datasets/"+dataset+"/testing_"+str(fold)+".txt";
# DATA + MODEL READING
data=common.readData(inFile);
model=common.load(outFile);
# PREDICTING
predicted=model.predict(data["features"])
probabilities=model.predict_proba(data["features"])
import numpy as np
scores=np.zeros(len(probabilities));
for i in range (0,len(probabilities)):
scores[i]=probabilities[i][1];
newPredicted=common.getHighestProbabilities(scores,data["webpageIndices"],top);
# OUTPUT STATISTICS
[resultString,binaryValues]=common.printStatistics(newPredicted,data["labels"],data["webpageIndices"]);
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/testing_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(resultString);
f.close();
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/binary_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(binaryValues);
f.close();
(5) MLP training and Testing
(5.1) MlP training
#MLP train and Test
# Trains a MLP model and stores it in a file
import common
import sys
from sklearn.neural_network import MLPClassifier
# PARAMETERS
output="../output/";
input="../input/";
inFile="train.txt";
outFile="/home/tko/himat/web-docs/machine_learning/classification/models/mlp.joblib";
if(len(sys.argv)>1):
dataset=sys.argv[1];
if(len(sys.argv)>2):
fold=int(sys.argv[2]);
inFile="/home/tko/himat/web-docs/machine_learning/txt_files_datasets/"+dataset+"/testing_"+str(fold)+".txt";
L1=15;
L2=15;
# DATA READING
data=common.readData(inFile);
# TRAINING
model = MLPClassifier(solver='lbfgs', alpha=1e-5,
hidden_layer_sizes=(L1, L2), random_state=1)
model.fit(data["features"][:-1], data["labels"][:-1])
# SAVING MODEL
common.save(model,outFile);
print ("Model saved at %s" % (outFile));
(5.2)MLP testing
# Reads a MLP model from a file and performs prediction
import common
import sys
from sklearn import svm
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import GridSearchCV
# PARAMETERS
inFile="../testing.txt";
outFile="/home/tko/himat/web-docs/machine_learning/classification/models/mlp.joblib";
top=10;#default
if(len(sys.argv)>1):
dataset=sys.argv[1];
if(len(sys.argv)>2):
fold=int(sys.argv[2]);
if(len(sys.argv)>3):
top=int(sys.argv[3]);
inFile="/home/tko/himat/web-docs/machine_learning/txt_files_datasets/"+dataset+"/testing_"+str(fold)+".txt";
# DATA + MODEL READING
data=common.readData(inFile);
model=common.load(outFile);
# PREDICTING
predicted=model.predict(data["features"])
probabilities=model.predict_proba(data["features"])
import numpy as np
scores=np.zeros(len(probabilities));
for i in range (0,len(probabilities)):
scores[i]=probabilities[i][1];
newPredicted=common.getHighestProbabilities(scores,data["webpageIndices"],top);
# OUTPUT STATISTICS
[resultString,binaryValues]=common.printStatistics(newPredicted,data["labels"],data["webpageIndices"]);
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/testing_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(resultString);
f.close();
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/binary_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(binaryValues);
f.close();
(6) SVM
(6.1)SVM train
# Trains an SVM model and stores it in a file
# grid optimization of parameters can be done
# 3.7.2019: RM - Implemented
import common
import sys
from sklearn import svm
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import GridSearchCV
# worry about this later
def getOptimizedParameters(features, labels):
import numpy as np
C_range = np.logspace(-2, 10, 13)
gamma_range = np.logspace(-9, 3, 13)
param_grid = dict(gamma=gamma_range, C=C_range)
cv = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=42)
grid = GridSearchCV(svm.SVC(), param_grid=param_grid, cv=cv)
grid.fit(features[:-1], labels[:-1])
return grid;
# leave it to 0 for now or study SVM parameter optimization
optimize=0;
# PARAMETERS
inFile="../training.txt";
outFile="/home/tko/himat/web-docs/machine_learning/classification/models/svm.joblib";
if(len(sys.argv)>1):
dataset=sys.argv[1];
if(len(sys.argv)>2):
fold=int(sys.argv[2]);
inFile="/home/tko/himat/web-docs/machine_learning/txt_files_datasets/"+dataset+"/testing_"+str(fold)+".txt";
# DATA READING
data=common.readData(inFile);
# OPTIMIZATION
if(optimize==1):
print ("Optimizing parameters");
parameters=getOptimizedParameters(data["features"],data["labels"]);
C=parameters.best_params_["C"];
gamma=parameters.best_params_["gamma"];
score=parameters.best_score_;
print("The best parameters are %s with a score of %0.2f"
% (parameters.best_params_, parameters.best_score_))
else:
# defaults
C= 10.0;
gamma=1000.0;
# TRAINING
model = svm.SVC(gamma=gamma, C=C, probability=True)
model.fit(data["features"], data["labels"])
# SAVING MODEL
common.save(model,outFile);
print ("Model saved at %s" % (outFile));
(6.2) SVM test
# Reads an SVM model from a file and performs prediction
import common
import sys
from sklearn import svm
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import GridSearchCV
# PARAMETERS
inFile="../testing.txt";
outFile="/home/tko/himat/web-docs/machine_learning/classification/models/svm.joblib";
top=10;#default
if(len(sys.argv)>1):
dataset=sys.argv[1];
if(len(sys.argv)>2):
fold=int(sys.argv[2]);
if(len(sys.argv)>3):
top=int(sys.argv[3]);
inFile="/home/tko/himat/web-docs/machine_learning/txt_files_datasets/"+dataset+"/testing_"+str(fold)+".txt";
# DATA + MODEL READING
data=common.readData(inFile);
model=common.load(outFile);
# PREDICTING
predicted=model.predict(data["features"])
probabilities=model.predict_proba(data["features"])
import numpy as np
scores=np.zeros(len(probabilities));
for i in range (0,len(probabilities)):
scores[i]=probabilities[i][1];
newPredicted=common.getHighestProbabilities(scores,data["webpageIndices"],top);
# OUTPUT STATISTICS
[resultString,binaryValues]=common.printStatistics(newPredicted,data["labels"],data["webpageIndices"]);
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/testing_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(resultString);
f.close();
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/binary_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(binaryValues);
f.close();
(7) Decesion Tree (DT)
(7.1) DT Train
# Trains a Decision Tree model and stores it in a file
# Number of neighbors is parameter
# 15.11.2018: RM - Implemented
# 3.12.2019: RM - Updated for Keywords
import common
import sys
from sklearn import tree, export_graphviz
# PARAMETERS
output="../output/";
input="../input/";
inFile="train.txt";
outFile="/home/tko/himat/web-docs/machine_learning/classification/models/dtree.joblib";
if(len(sys.argv)>1):
dataset=sys.argv[1];
if(len(sys.argv)>2):
fold=int(sys.argv[2]);
inFile="/home/tko/himat/web-docs/machine_learning/txt_files_datasets/"+dataset+"/testing_"+str(fold)+".txt";
# DATA READING
data=common.readData(inFile);
# TRAINING
model = tree.DecisionTreeClassifier()
model.fit(data["features"][:-1], data["labels"][:-1])
dot_data = export_graphviz(model,
out_file=None,
filled=True,
rounded=True)
pydot_graph = pydotplus.graph_from_dot_data(dot_data)
pydot_graph.write_png('original_tree.png')
pydot_graph.set_size('"5,5!"')
pydot_graph.write_png('resized_tree.png')
# SAVING MODEL
common.save(model,outFile);
print ("Model saved at %s" % (outFile));
(7.2) DT test
# Reads a Decision Tree model from a file and performs prediction
import common
import sys
from sklearn import svm
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import GridSearchCV
# PARAMETERS
output="../output/";
input="../input/";
inFile="test.txt";
outFile="/home/tko/himat/web-docs/machine_learning/classification/models/dtree.joblib";
top=10;#default
if(len(sys.argv)>1):
dataset=sys.argv[1];
if(len(sys.argv)>2):
fold=int(sys.argv[2]);
if(len(sys.argv)>3):
top=int(sys.argv[3]);
inFile="/home/tko/himat/web-docs/machine_learning/txt_files_datasets/"+dataset+"/testing_"+str(fold)+".txt";
# DATA + MODEL READING
data=common.readData(inFile);
model=common.load(outFile);
# PREDICTING
predicted=model.predict(data["features"])
probabilities=model.predict_proba(data["features"])
import numpy as np
scores=np.zeros(len(probabilities));
for i in range (0,len(probabilities)):
scores[i]=probabilities[i][1];
newPredicted=common.getHighestProbabilities(scores,data["webpageIndices"],top);
# OUTPUT STATISTICS
[resultString,binaryValues]=common.printStatistics(newPredicted,data["labels"],data["webpageIndices"]);
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/testing_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(resultString);
f.close();
outFile="/home/tko/himat/web-docs/machine_learning/classification/output/"+dataset+"/binary_"+str(fold)+".txt";
f= open(outFile,"w+");
f.write(binaryValues);
f.close();
(8) Generate Keywords from training and testing files
#php starts
$datasets=["guardian","macworld","mopsi_services"];//guardian,mopsi_services,macworld
$tops=[10,10,5];//guardian,mopsi_services,macworld
$outputDir = "/home/tko/himat/web-docs/machine_learning/classification/output";
$inputDir = "/home/tko/himat/web-docs/machine_learning/txt_files_datasets";
$classifiersDir = "/home/tko/himat/web-docs/machine_learning/classification/classifiers/";
$classificationMethod="max_scoring.py";// means Drank
$classificationMethod="knn";
$neighbors=12;
$classificationMethod="dtree";
/*$classificationMethod="bayes";
$classificationMethod="mlp";
$classificationMethod="svm";*/
for($d=0;$d< count($datasets);$d++){
$dataset=$datasets[$d];
$allResults=[];
for($k=1;$k<=5;$k++){
if($classificationMethod=="knn"){
$output = shell_exec('python3 '.$classifiersDir.$classificationMethod."_train.py ".$dataset." ".$k." ".$neighbors);
$output = shell_exec('python3 '.$classifiersDir.$classificationMethod."_test.py ".$dataset." ".$k." ".$tops[$d]);
}else if($classificationMethod=="dtree"){
$output = shell_exec('python3 '.$classifiersDir.$classificationMethod."_train.py ".$dataset." ".$k);
$output = shell_exec('python3 '.$classifiersDir.$classificationMethod."_test.py ".$dataset." ".$k." ".$tops[$d]);
}else if($classificationMethod=="bayes"){
$output = shell_exec('python3 '.$classifiersDir.$classificationMethod."_train.py ".$dataset." ".$k);
$output = shell_exec('python3 '.$classifiersDir.$classificationMethod."_test.py ".$dataset." ".$k." ".$tops[$d]);
}else if($classificationMethod=="mlp"){
$output = shell_exec('python3 '.$classifiersDir.$classificationMethod."_train.py ".$dataset." ".$k);
$output = shell_exec('python3 '.$classifiersDir.$classificationMethod."_test.py ".$dataset." ".$k." ".$tops[$d]);
}else if($classificationMethod=="svm"){
$output = shell_exec('python3 '.$classifiersDir.$classificationMethod."_train.py ".$dataset." ".$k);
$output = shell_exec('python3 '.$classifiersDir.$classificationMethod."_test.py ".$dataset." ".$k." ".$tops[$d]);
}else{ //drank
$output = shell_exec('python3 '.$classifiersDir.$classificationMethod." ".$dataset." ".$k." ".$tops[$d]);
}
$results=readResults($outputDir."/".$dataset."/testing_".$k.".txt");
$keywords=readKeywords($inputDir."/".$dataset."/testing_kw_".$k.".txt"); // reads keywords from separate file
for($i=0;$i0){
$str.="\n";
}
for($j=0;$j0){
$str.=" ";
}
$str.=$results[$i][$j];
}
}
return $str;
}
#PHP ends
(9) Database setup
#-php program
#datasetup.py (Generate the testing and training data in txt in txt_files_datasets)
php Starts
// here we prepare training and testing data from raw information
// 3.7.2019 : RM - Implemented
// 28.10.2019: RM - updating to output keywords in separate files
/* input file format
Word,TF,H1,H2,H3,H4,H5,H6,Anchor,Title,URL-1,Url-2,Text Length,GT,webpag_id
0-Word: total words appear in the text of the webpage
1-TF: Term Frequency of the word how many times a particular word appearing
2:7-H1-H6:Header tags
8-Anchor: A text appeared inside Anchor tag
9-Title: title tag
10-Url-1: Host part of the url or main part of the url
11-Url-2: Query part of url after the /
12-Text Length: total no of words inside the webpage
13-GT:Ground truth matching words
14-Webpage_id:Represent unique id for each webpage
*/
// file is big, need extra memory
ini_set('memory_limit', '15192M');
// read input
$inputFileName="csv_files/mopsi_services_312.csv";//mopsi_services_414.csv,macworld_220.csv,guardian_412.csv
$outputDirectory="mopsi_services";//mopsi_services,macworld,guardian
$myfile = fopen($inputFileName, "r") or die("Unable to open file!");
$contents = fread($myfile,filesize($inputFileName));
fclose($myfile);
// dividing into lines
$lines=explode("\n",$contents);
echo count($lines)." lines\n";
// grouping into webpages
$pages=[];
$page=[];
$webId=-1;
for($i=0;$i< count($lines);$i++){
$comp=explode(",",$lines[$i]);
$webpag_id=trim($comp[14]);
if($webpag_id!="" && $webpag_id!="webpag_id" && $webpag_id!="web-id"){/// HIMAT FIX
if($webId!=$webpag_id){
$webId=$webpag_id;
if(count($page)>0){
array_push($pages,$page);
}
$page=[];
}
array_push($page,$lines[$i]);
}else{
//ignoring some header repeating or empty line
}
}
if(count($page)>0){
array_push($pages,$page);
}
echo count($pages)." pages\n";
// dividing into train / test
$testingPercent=0.2;
for($k=0;$k< 5;$k++){
$training=[];
$testing=[];
$lowThreshold=floor($testingPercent*$k*count($pages));
$highThreshold=floor($testingPercent*($k+1)*count($pages));
for($i=0;$i< count($pages);$i++){
if($i>=$lowThreshold && $i<$highThreshold){
array_push($testing,$pages[$i]);
}else{
array_push($training,$pages[$i]);
}
}
//echo count($training)." training\n";
//echo count($testing)." testing\n";
// generate the feature vector files
$trainingFileName="txt_files_datasets/$outputDirectory/training_".($k+1).".txt";
$myfile = fopen($trainingFileName, "w") or die("Unable to open file!");
fwrite($myfile, formatFileContents($training));
fclose($myfile);
$testingFileName="txt_files_datasets/$outputDirectory/testing_".($k+1).".txt";
$myfile = fopen($testingFileName, "w") or die("Unable to open file!");
fwrite($myfile, formatFileContents($testing));
fclose($myfile);
// generate the keyword mapping files
$trainingFileName="txt_files_datasets/$outputDirectory/training_kw_".($k+1).".txt";
$myfile = fopen($trainingFileName, "w") or die("Unable to open file!");
fwrite($myfile, formatKeywordFileContents($training));
fclose($myfile);
$testingFileName="txt_files_datasets/$outputDirectory/testing_kw_".($k+1).".txt";
$myfile = fopen($testingFileName, "w") or die("Unable to open file!");
fwrite($myfile, formatKeywordFileContents($testing));
fclose($myfile);
}
function formatFileContents($pages){
$string="";
for($i=0;$i< count($pages);$i++){
for($j=0;$j< count($pages[$i]);$j++){
$line=$pages[$i][$j];
// generating feature vector
$comp=explode(",",$line);
$vector=[];
for($k=1;$k< count($comp);$k++){
// no need for word itself starting at 1
array_push($vector,trim($comp[$k]));
}
for($k=0;$k< count($vector);$k++){
$string.=$vector[$k];
if($k< count($vector)-1){
$string.=" ";
}else{
$string.="\n";
}
}
}
}
return $string;
}
function formatKeywordFileContents($pages){
$string="";
for($i=0;$i< count($pages);$i++){
for($j=0;$j< count($pages[$i]);$j++){
$line=$pages[$i][$j];
// generating feature vector
$comp=explode(",",$line);
$vector=[];
array_push($vector,trim($comp[0]));
for($k=0;$k< count($vector);$k++){
$string.=$vector[$k];
if($k< count($vector)-1){
$string.=" ";
}else{
$string.="\n";
}
}
}
}
return $string;
}
PHP ends>
(10) Test php file
PHP starts
// here we prepare training and testing data from raw information
// 3.7.2019 : RM - Implemented
// 28.10.2019: RM - updating to output keywords in separate files
/* input file format
Word,TF,H1,H2,H3,H4,H5,H6,Anchor,Title,URL-1,Url-2,Text Length,GT,webpag_id
0-Word: total words appear in the text of the webpage
1-TF: Term Frequency of the word how many times a particular word appearing
2:7-H1-H6:Header tags
8-Anchor: A text appeared inside Anchor tag
9-Title: title tag
10-Url-1: Host part of the url or main part of the url
11-Url-2: Query part of url after the /
12-Text Length: total no of words inside the webpage
13-GT:Ground truth matching words
14-Webpage_id:Represent unique id for each webpage
*/
// file is big, need extra memory
ini_set('memory_limit', '15192M');
// read input//mopsi_services_414.csv,macworld_204.csv,guardian_412.csv
$outputDirectory="combined";
$inputFileName="csv_files/guardian_402.csv";
$myfile = fopen($inputFileName, "r") or die("Unable to open file!");
$contents = fread($myfile,filesize($inputFileName));
fclose($myfile);
// dividing into lines
$lines1=explode("\n",$contents);
echo count($lines1)." lines\n";
$inputFileName="csv_files/macworld_204.csv";
$myfile = fopen($inputFileName, "r") or die("Unable to open file!");
$contents = fread($myfile,filesize($inputFileName));
fclose($myfile);
// dividing into lines
$lines2=explode("\n",$contents);
echo count($lines2)." lines\n";
$inputFileName="csv_files/mopsi_services_312.csv";
$myfile = fopen($inputFileName, "r") or die("Unable to open file!");
$contents = fread($myfile,filesize($inputFileName));
fclose($myfile);
// dividing into lines
$lines3=explode("\n",$contents);
echo count($lines3)." lines\n";
$lines=[];
for($i=0;$i< count($lines1);$i++){
array_push($lines,$lines1[$i]);
}
for($i=0;$i< count($lines2);$i++){
array_push($lines,$lines2[$i]);
}
for($i=0;$i< count($lines3);$i++){
array_push($lines,$lines3[$i]);
}
// grouping into webpages
$pages=[];
$page=[];
$webId=-1;
for($i=0;$i0){
array_push($pages,$page);
}
$page=[];
}
array_push($page,$lines[$i]);
}else{
//ignoring some header repeating or empty line
}
}
if(count($page)>0){
array_push($pages,$page);
}
echo count($pages)." pages\n";
// dividing into train / test
$testingPercent=0.2;
for($k=0;$k< 5;$k++){
$training=[];
$testing=[];
$lowThreshold=floor($testingPercent*$k*count($pages));
$highThreshold=floor($testingPercent*($k+1)*count($pages));
for($i=0;$i< count($pages);$i++){
if($i>=$lowThreshold && $i<$highThreshold){
array_push($testing,$pages[$i]);
}else{
array_push($training,$pages[$i]);
}
}
//echo count($training)." training\n";
//echo count($testing)." testing\n";
// generate the feature vector files
$trainingFileName="txt_files_datasets/$outputDirectory/training_".($k+1).".txt";
$myfile = fopen($trainingFileName, "w") or die("Unable to open file!");
fwrite($myfile, formatFileContents($training));
fclose($myfile);
$testingFileName="txt_files_datasets/$outputDirectory/testing_".($k+1).".txt";
$myfile = fopen($testingFileName, "w") or die("Unable to open file!");
fwrite($myfile, formatFileContents($testing));
fclose($myfile);
// generate the keyword mapping files
$trainingFileName="txt_files_datasets/$outputDirectory/training_kw_".($k+1).".txt";
$myfile = fopen($trainingFileName, "w") or die("Unable to open file!");
fwrite($myfile, formatKeywordFileContents($training));
fclose($myfile);
$testingFileName="txt_files_datasets/$outputDirectory/testing_kw_".($k+1).".txt";
$myfile = fopen($testingFileName, "w") or die("Unable to open file!");
fwrite($myfile, formatKeywordFileContents($testing));
fclose($myfile);
}
function formatFileContents($pages){
$string="";
for($i=0;$i< count($pages);$i++){
for($j=0;$j< count($pages[$i]);$j++){
$line=$pages[$i][$j];
// generating feature vector
$comp=explode(",",$line);
$vector=[];
for($k=1;$k< count($comp);$k++){
// no need for word itself starting at 1
array_push($vector,trim($comp[$k]));
}
for($k=0;$k< count($vector);$k++){
$string.=$vector[$k];
if($k< count($vector)-1){
$string.=" ";
}else{
$string.="\n";
}
}
}
}
return $string;
}
function formatKeywordFileContents($pages){
$string="";
for($i=0;$i< count($pages);$i++){
for($j=0;$j< count($pages[$i]);$j++){
$line=$pages[$i][$j];
// generating feature vector
$comp=explode(",",$line);
$vector=[];
array_push($vector,trim($comp[0]));
for($k=0;$k < count($vector);$k++){
$string.=$vector[$k];
if($k< count($vector)-1){
$string.=" ";
}else{
$string.="\n";
}
}
}
}
return $string;
}
End php>
#
# removes the non existing files without tags
#rename the files
# 220 to 204 reduced
# change the numbers into binary files
import dranks as D
from nltk.corpus import stopwords
import re
stp ="january use jun jan feb mar apr may jul agust dec oct nov sep dec product continue one two three four five please thanks find helpful week job experience women girl apology read show eve knowledge benefit appointment street way staff salon discount gift cost thing world close party love letters rewards offers special close page week dollars voucher gifts vouchers welcome therefore march nights need name pleasure show sisters thank menu today always time needs welcome march february april may june jully aguast september october november december day year month minute second secodns".split(" ")
common_nouns='debt est dec big than who of com offer sale the in fi'.split(" ")
stps=set(stopwords.words("english"))
spchars = re.compile('\`|\~|\!|\@|\#|\$|\%|\^|\&|\*|\(|\)|\_|\+|\=|\\|\||\{|\[|\]|\}|\:|\;|\'|\"|\<|\,|\>|\?|\/|\.|\- ')
from collections import defaultdict
from flask import Flask
import requests
from bs4 import BeautifulSoup
import dranks as D
import warnings
warnings.filterwarnings("ignore")
import csv
###########################################################################################################################################
import re
spchars = re.compile('\`|\~|\!|\@|\#|\$|\%|\^|\&|\*|\(|\)|\_|\+|\=|\\|\||\{|\[|\]|\}|\:|\;|\'|\"|\<|\,|\>|\?|\/|\.|\- ’')
import dranks as D
stp ="january use jun jan feb mar apr may jul agust dec free oct nov sep dec product continue one two three four five please thanks find helpful week job experience women girl apology read show eve knowledge benefit appointment street way staff salon discount gift cost thing world close party love letters rewards offers special close page week dollars voucher gifts vouchers welcome therefore march nights need name pleasure show sisters thank menu today always time needs welcome march february april may june jully aguast september october november december day year month minute second secodns".split(" ")
common_nouns=['debt', 'est' 'dec' ,'big' ,'than', 'who','one','two','three','of','four','five','al sisi','free','gift','voucher','vouchers','try','best buy buying']
common_words =['of','for','the','www','fi','com','free','try','best']
name_of_file=['germon_stopwords_file','finnish_stopwords_file','english_stpwords_list']
germon_stopwords_file=D.Stop_Words_list(name_of_file[0])
finnish_stopwords_file=D.Stop_Words_list(name_of_file[1])
english_stpwords=D.Stop_Words_list(name_of_file[2])
stop_word_list =[english_stpwords, finnish_stopwords_file, germon_stopwords_file]
##################################################################################################
def Clean_text(text):
Words =[]
for word in text.split():
word = word.replace("’",' ')
word = word.lower()
word = spchars.sub(" ",word.strip())
if word not in stps:
if word not in stp:
if len(word)>1:
if word != " ":
if word not in common_nouns:
if not word.isdigit():
if word not in stop_word_list[0]:
for x in word.split():
if x not in stp and x not in stps and len(x)>1 and x not in common_nouns and x not in common_words:
x = x.strip()
if not x[0].isdigit():
Words.append(x)
return (Words)
def Remove_duplicates_GT(l):
new_list =[]
[new_list.append(x) for x in l if x not in new_list]
return (new_list)
def Clean_CSV_Files(words):
w=[]
import string
from string import digits
exclude = set(string.punctuation)
if type(words) is not list:
words = [(spchars.sub(" ", i)).replace('\n','').strip().lstrip(digits)for i in words.split(',') if i not in exclude ]
else:
words =[(spchars.sub(" ", i)).replace('\n','').strip().lstrip(digits)for i in words if i not in exclude ]
for x in words:
if len(x)>0:
w.append(x)
return(w)
def Tf_Score(fr,text_length):
if text_length < 50:
tf_score =((fr/100)*50)
else:
tf_score=((fr/100)*20)
return (tf_score)
def Feature_Score(candidate_word,feature_words,score):
total_score=0
score_single_time =0
for word_feature in feature_words:
if word_feature ==candidate_word:
#total_score+=score
score_single_time = score
return(score_single_time)
###############################################################################################
def Get_guardian_url_words_list(root):
Score =defaultdict()
csv.register_dialect('myDialect',delimiter = ',', quoting=csv.QUOTE_NONE, skipinitialspace=True)
stop_word_list =[english_stpwords, finnish_stopwords_file, germon_stopwords_file]
with open('guardian_402.csv', 'a',encoding ='utf-8') as f:
writer = csv.writer(f, dialect='myDialect')
writer.writerow(['Word','TF','H1','H2','H3','H4','H5','H6','Anchor','Title','Url-Host','Url-Query','Txt-Lngth','GT','web-id'])
for web_id in range(402):
try:
files= root + str(web_id) + '/tags.txt'
urls,GT=D.Read_Txt(files) # seperates the ground truth and url
url=str(urls)
text,HTML = D.Web(url)
H1, H2, H3, H4, H5, H6, anchor, title = D.Extract_headerAnchorTitle(HTML)
url_host, url_query = D.Urls(url)
words =Clean_text(text)
text_length =len(words)
words_and_freq = D.Calc_word_frequency(words)
score = []
in_gt =0
for word,fr in words_and_freq.items():
score_h1 = Feature_Score(word,H1,1) #6
score_h2 = Feature_Score(word,H2,1)#5
score_h3 = Feature_Score(word,H3,1)#3
score_h4 = Feature_Score(word,H4,1)#2
score_h5 = Feature_Score(word,H5,1)#2
score_h6 = Feature_Score(word,H6,1)#2
score_anchor = Feature_Score(word,anchor,1)#1
score_title = Feature_Score(word,title,1)#6
score_url_host = Feature_Score(word,url_host,1)#5
score_url_query = Feature_Score(word,url_query,1)#4
tf_score = Tf_Score(fr,text_length)
if word not in GT:
in_gt = 0
else:
in_gt = 1
writer.writerow([word,str(fr),str(score_h1),str(score_h2),str(score_h3),str(score_h4),str(score_h5),str(score_h6),str(score_anchor),str(score_title),str(score_url_host),str(score_url_query),str(text_length),str(in_gt),str(web_id)])
#score =word,str(fr),str(score_h1),str(score_h2),str(score_h3),str(score_h4),str(score_h5),str(score_h6),str(score_anchor),str(score_title),str(score_url_host),str(score_url_query),str(text_length),str(in_gt),str(web_id)]
#print ([word,str(fr),str(score_h1),str(score_h2),str(score_h3),str(score_h4),str(score_h5),str(score_h6),str(score_anchor),str(score_title),str(score_url_host),str(score_url_query),str(text_length),str(in_gt),str(web_id)])
except:
print (web_id)
pass
##############################################################################################################
root ='/home/tko/himat/web-docs/keywordextraction/dataset2/theguardian/'
from collections import defaultdict,Counter
Get_guardian_url_words_list(root)
#####################################################################################################
def Rename_files(path):
import os
files = os.listdir(path)
i = 0
for file in files:
os.rename(os.path.join(path, file), os.path.join(path, str(i)))
i = i+1
#path=r'/home/tko/himat/web-docs/keywordextraction/sets/indianexpress/'
#Rename_files(root)
###########################################################################
import os
def File_exists(root,ranges):
for x in range (ranges):
my_path = root + str(x) + '/tags.txt'
if os.path.exists(my_path) and os.path.getsize(my_path) > 0:
p =0
else:
print (x)
####################################################################################
#Creating the ground truth (GT) txt file f
def GT_txt():
txt_file = open('gt.txt','w',encoding ='utf-8')
for web_id in range(402):
files= root + str(web_id) + '/tags.txt'
urls,GT=D.Read_Txt(files)
GT =' '.join(GT)
txt_file.write(str(web_id) + ' ' + str(GT) + '\n')
print (GT)
print ('---------------------',web_id)
txt_file.close()